Reinforcement Learning¶
As we provide standard RL-like interfaces, one can implement any RL algorithm on top of it in a neat manner. Before algorithm implementation, it should be noted what problem is to be solved. To formulate desired problems, we follow the Formulation as Wrappers principle by encoding appropriate wrappers.
Tabular RL¶
Single-Agent Q Learning¶
Given a particular agent and the multi-agent environment, a single-agent RL problem can be induced. One can simply assume the others are not moving and compute an optimal policy for that particular agent.
from marp.rl import SingleAgentLearningWrapper, Qlearning
env.reset()
ctrl_agent = 'robot_1'
training_env = SingleAgentLearningWrapper(env, ctrl_agent)
policy = Qlearning(training_env)
observations, infos = env.reset()
while env.agents:
a = policy[str(observations[ctrl_agent])] if str(observations[ctrl_agent]) in policy else 0
actions = {
agent: a if agent == ctrl_agent else 0
for agent in env.agents
}
observations, rewards, terminations, truncations, infos = env.step(actions)
env.render()
The above code has basically done the following things:
Formulate a single-agent RL problem from
robot_1’s perspective by the wrapperSingleAgentLearningWrapper.Call
Qlearning()to compute a policy.Execute the policy.
One will probably get similar visual results as follows. Note that we simple assume all other agents stay put.
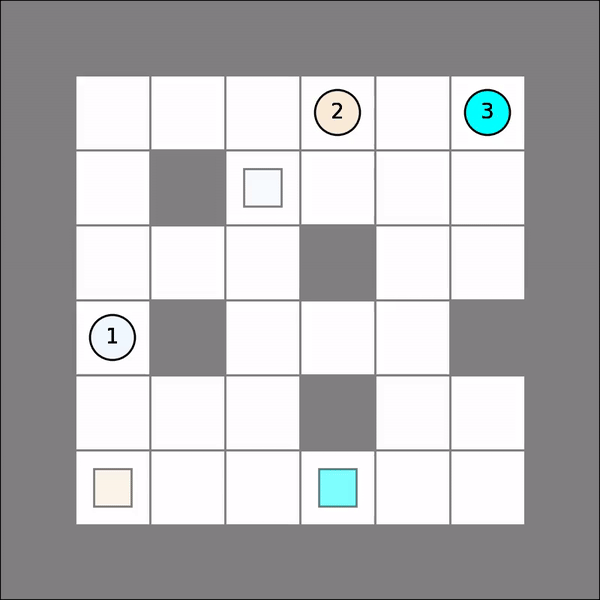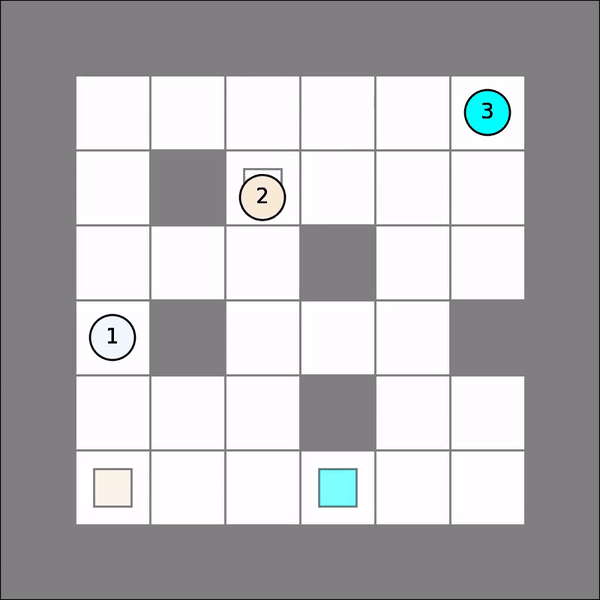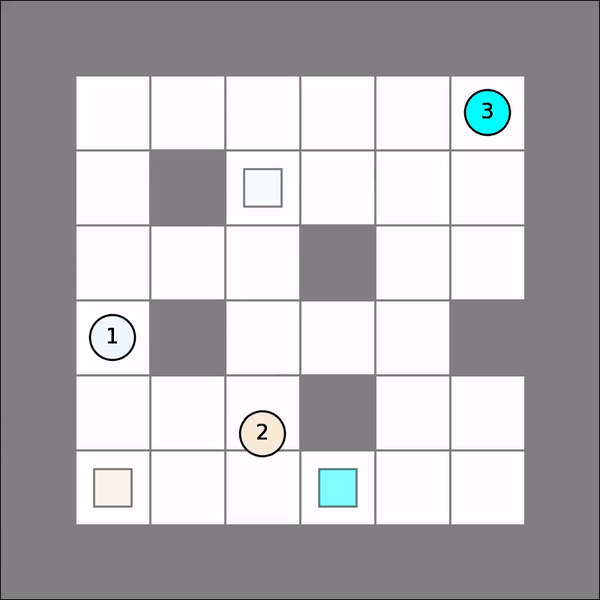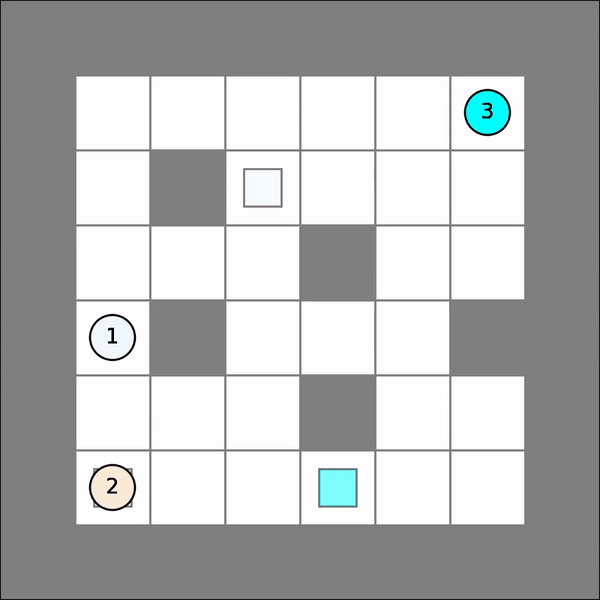
Multi-Agent Joint Q Learning¶
One can also view all agents as a joint one, to find an optimal policy for the joint agent is to find a policy for each agent as if they are all under centralized control.
from marp.rl import MultiAgentJointLearningWrapper, Qlearning
env.reset()
training_env = MultiAgentJointLearningWrapper(env)
ja = training_env.joint_actions
policy = Qlearning(training_env, num_it=3e4, alpha=0.8)
observations, infos = env.reset()
while env.agents:
a = policy[str(observations[env.agents[0]])] if str(observations[env.agents[0]]) in policy else 0
actions = dict(zip(env.agents, ja[a]))
observations, rewards, terminations, truncations, infos = env.step(actions)
env.render()
The above code has basically done the following things:
Formulate a multi-agent joint learning problem by the wrapper
MultiAgentJointLearningWrapper.Again, call
Qlearning()to compute a (joint) policy, since we are still dealing with one (joint) agent.Execute the policy.
One will probably get similar visual results as follows. Note that this time Qlearning() operates over joint state space and joint action space with certain aggregated rewards, and therefore, may not perform well if it is not trained for enough iterations.
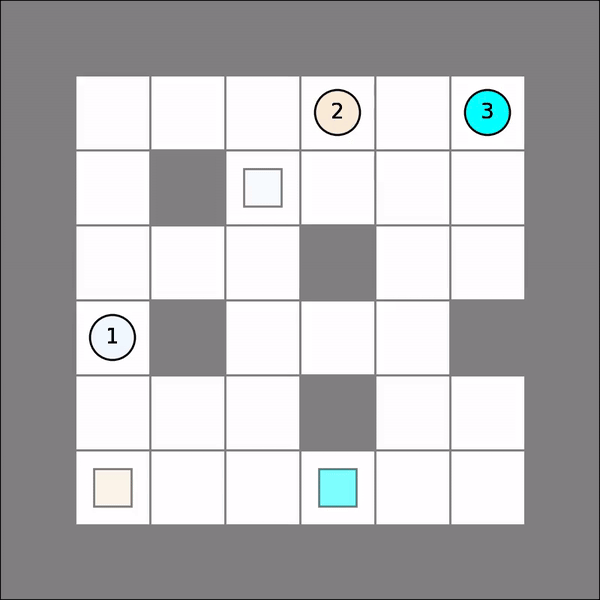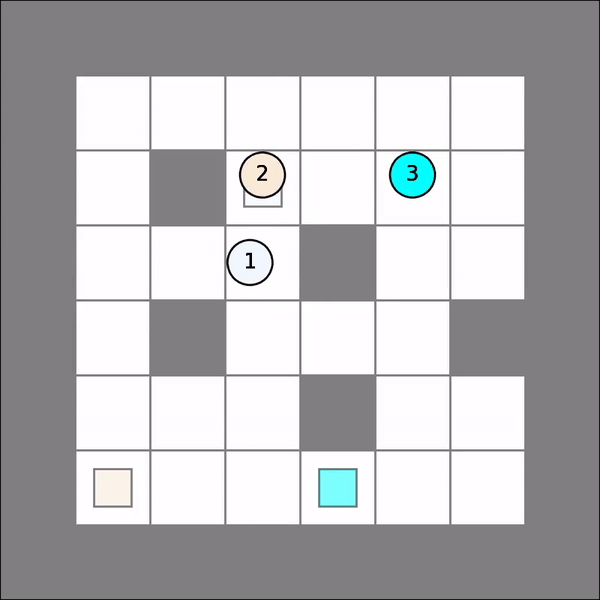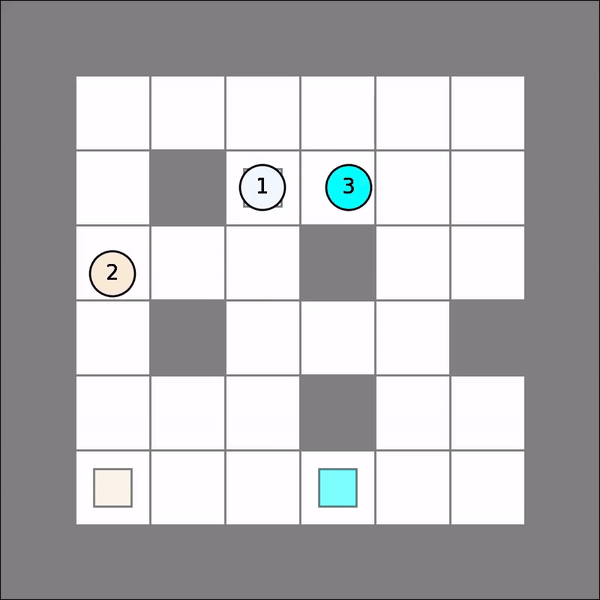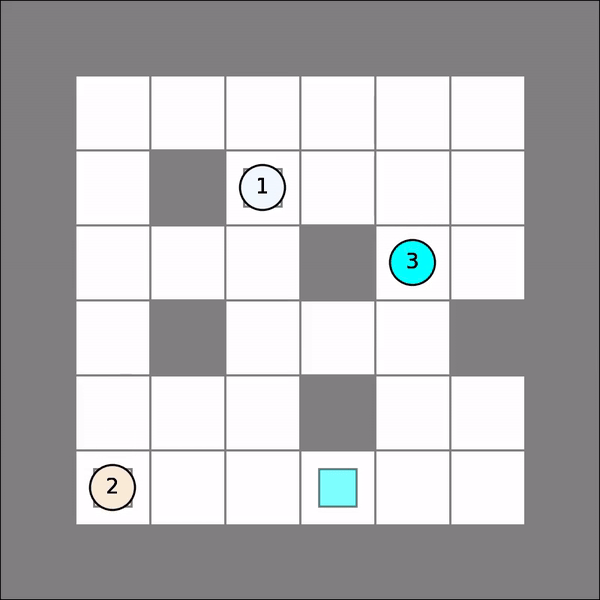
Multi-Agent Individual Q Learning¶
To achive centralized control, one can alternatively view each agent as an autonomous entity interacting with others. Each of them learns am individual policy even if the interaction is non-stationary.
from marp.rl import individualQlearning
env.reset()
policies = individualQlearning(env, num_it=5e4, epsilon=0.5, alpha=0.3)
observations, infos = env.reset()
while env.agents:
actions = {}
for agent in env.agents:
if str(observations[agent]) not in policies[agent]:
actions[agent] = 0
else:
actions[agent] = policies[agent][str(observations[agent])]
observations, rewards, terminations, truncations, infos = env.step(actions)
env.render()
The above code has basically done the following things:
Just take the raw multi-agent environment.
Instead, call
individualQlearning()to compute individual policies for each agent.Execute the policy profile.
Note that for each agent, her policy is a mapping from possible joint states to her own actions. One will probably get similar visual results as follows. As shown, agent 2 took greedy moves at first but then make a detour to avoid collision with agent 1.
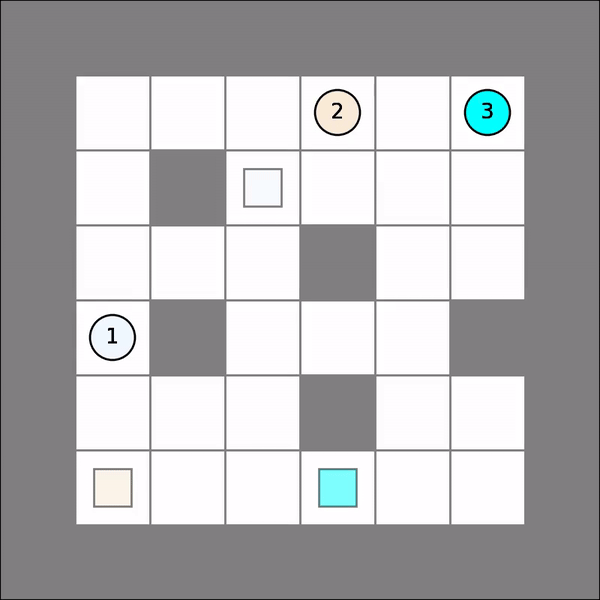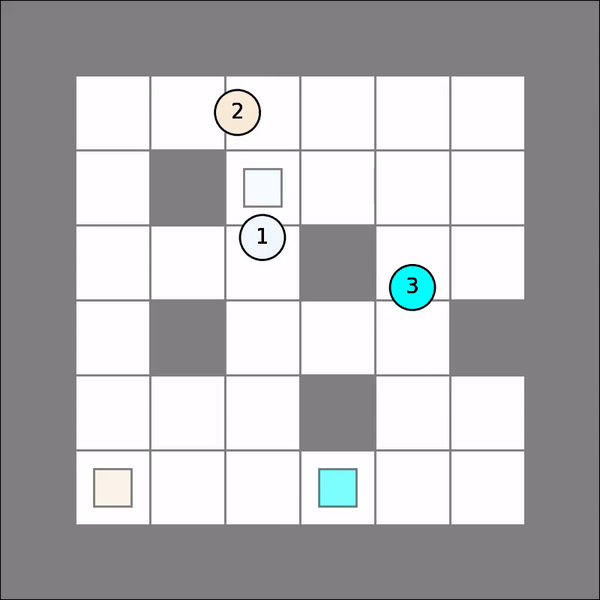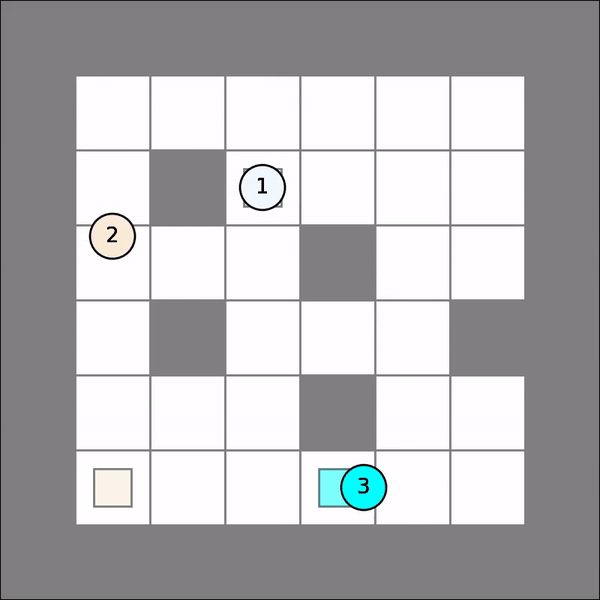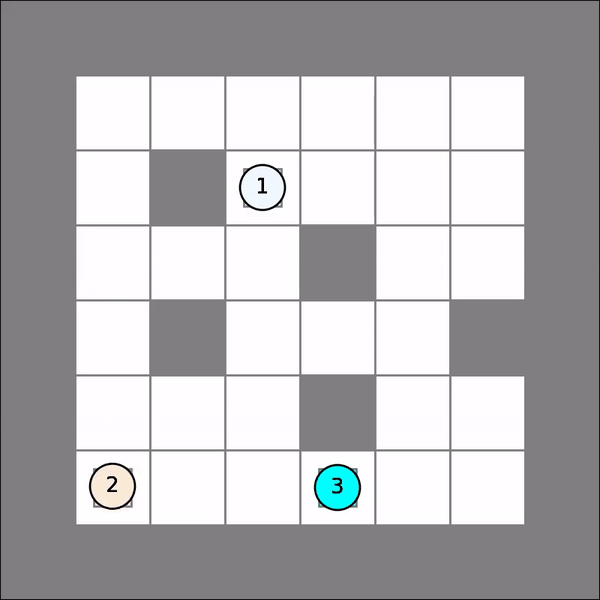
Deep RL¶
In addition to conventional tabular RL implementations, one can also take one step further by integrating existing deep RL algorithms, e.g., DQN, A2C, and PPO.
We hereby also provide a tutorial by using Stable Baselines3 as a pool of Deep RL algorithms, and SuperSuit as useful environment wrappers for parallel training.
Single-Agent DRL¶
import time
import numpy as np
import supersuit as ss
from stable_baselines3 import DQN
from marp.rl import SingleAgentLearningWrapper
alg = DQN
policy_kwargs = {
'net_arch': [8, 2],
}
agent = 'robot_0'
env.reset()
training_env = SingleAgentLearningWrapper(env, agent)
training_env = ss.stable_baselines3_vec_env_v0(training_env, num_envs=8)
training_env.reset()
model = alg("MlpPolicy", training_env,
verbose=1,
tau=0.5,
exploration_fraction=0.5,
batch_size=256,
policy_kwargs=policy_kwargs,
tensorboard_log="runs")
model.learn(total_timesteps=int(2.5e6),
tb_log_name=f"{time.strftime('%Y-%m-%d-%H%M%S', time.localtime())}")
model.save(f"pretrained/singleDQN_{agent}")
policy = alg.load(f"pretrained/singleDQN_{agent}.zip")
observations, infos = env.reset()
while env.agents:
actions = {
'robot_0': policy.predict(observations['robot_0'], deterministic=True)[0]
}
actions['robot_1'] = 0
actions['robot_2'] = 0
observations, rewards, terminations, truncations, infos = env.step(actions)
env.render()
Multi-Agent Joint Learning¶
import time
import numpy as np
import supersuit as ss
from stable_baselines3 import PPO
from marp.rl import MultiAgentJointLearningWrapper
alg = PPO
policy_kwargs = {
'net_arch': dict(pi=[16, 6], vf=[16, 6]),
}
training_env = MultiAgentJointLearningWrapper(env)
ja = training_env.joint_actions
training_env = ss.stable_baselines3_vec_env_v0(training_env, num_envs=8)
training_env.reset()
model = alg("MlpPolicy", training_env,
verbose=1,
batch_size=128,
policy_kwargs=policy_kwargs,
tensorboard_log="runs")
model.learn(total_timesteps=int(10e6),
tb_log_name=f"{time.strftime('%Y-%m-%d-%H%M%S', time.localtime())}")
model.save("pretrained/jointPPO")
model = alg.load("pretrained/jointPPO.zip")
observations, infos = env.reset()
while env.agents:
a, _ = model.predict(observations[env.agents[0]])
actions = ja[a]
actions = dict(zip(env.agents, actions))
observations, rewards, terminations, truncations, infos = env.step(actions)
env.render()
Multi-Agent Individual Learning¶
import time
import supersuit as ss
from stable_baselines3 import A2C
alg = A2C
training_env = ss.pettingzoo_env_to_vec_env_v1(env)
training_env = ss.concat_vec_envs_v1(training_env, 8, num_cpus=1, base_class="stable_baselines3")
training_env.reset()
model = alg("MlpPolicy", training_env,
verbose=1,
tensorboard_log="runs")
model.learn(total_timesteps=int(8e6),
tb_log_name=f"{time.strftime('%Y-%m-%d-%H%M%S', time.localtime())}")
model.save("pretrained/indiA2C")
model = alg.load("pretrained/indiA2C.zip")
observations, infos = env.reset()
while env.agents:
actions = {
agent: model.predict(observations[agent], deterministic=True)[0]
for agent in env.agents
}
observations, rewards, terminations, truncations, infos = env.step(actions)
env.render()
Detailed Usage¶
Functions¶
- marp.rl.Qlearning(env, num_it=1000.0, epsilon=0.5, alpha=0.3, gamma=0.9)¶
Tabular Q learning
- Parameters:
env (RLEnv) – a single/joint-agent RL environment
num_it (int or float) – the number of learning iterations
epsilon (float) – the initial exploration rate, will linearly decay to 0.1 in the first half of iterations
alpha (float) – learning rate
gamma (float) – discount factor
- Returns:
policy (dict) – the learned policy
- marp.rl.individualQlearning(env, num_it=1000.0, epsilon=0.5, alpha=0.3, gamma=0.9)¶
Tabular Q learning for multiple individual learners
- Parameters:
env (MARLEnv) – a multi-agent RL environment
num_it (int or float) – the number of learning iterations
epsilon (float) – the initial exploration rate, will linearly decay to 0.1 in the first half of iterations
alpha (float) – learning rate
gamma (float) – discount factor
- Returns:
policies (dict[str, dict]) – a policy profile
Classes¶
- class marp.rl.SingleAgentLearningWrapper(ma_env, agent)¶
Formulate a single agent learning problem
- Parameters:
ma_env (MARP) – an intialized multi-agent environment
agent (str) – the agent the the problem is induced for
- reset(seed=None, options=None)¶
Reset the location of the agent
- step(action)¶
Proceed to the next step by the given action
- Parameters:
action (Action) – the next action
- Returns:
obs (dict) – local observation
reward (float) – reward
termination (bool) – whether the episode terminates
truncation (bool) – whether the maximum number of steps is exceeded
info (dict) – auxiliary infomation including collision situations and action masks
- class marp.rl.MultiAgentJointLearningWrapper(ma_env)¶
Formulate a multi-agent joint learning problem
- Parameters:
ma_env (MARP) – an intialized multi-agent environment
- reset(seed=None, options=None)¶
Reset the locations of agents
- step(action)¶
Proceed to the next step by the given joint action
- Parameters:
action (Action) – the next joint action
- Returns:
obs (dict) – joint observations
reward (float) – aggregated reward by simple summation
termination (bool) – whether the episode terminates for all agents
truncation (bool) – whether the maximum number of steps is exceeded
info (dict) – auxiliary infomation including collision situations and action masks