Search¶
As we mentioned in the Quick Start, in addition to RL-related interfaces, we have also provide with search-related interfaces.
The search problem underneath the environment is to find collision-free paths for each agent, a path for an agent is a sequence of actions from her initial location to her designated goal location. To formulate a search problem for each agent, we again follow the Formulation as Wrappers principle by encoding wrappers.
Path-Finding for Individual Agents¶
Suppose a MARP environment has been intialized, one can induce a single-agent search problem by ingoring others.
env.reset()
from marp.search import SingleAgentSearchWrapper, astar
plans = {}
for agent in env.agents:
plans[agent] = astar(SingleAgentSearchWrapper(env, agent))
while env.agents:
actions = {}
for agent in env.agents:
path = plans[agent]
if len(path):
actions[agent] = path.pop(0)
else:
actions[agent] = 0
observations, rewards, terminations, truncations, infos = env.step(actions)
The above code has done the following things:
Formulate a single-agent search problem for each agent by the wrapper
SingleAgentSearchWrapperCall A star search algorithm
astar()to compute a plan (path) for each agent.Execute the plans.
One will probably get similar visual results as follows. Note that there might be collisions (agents turning red).
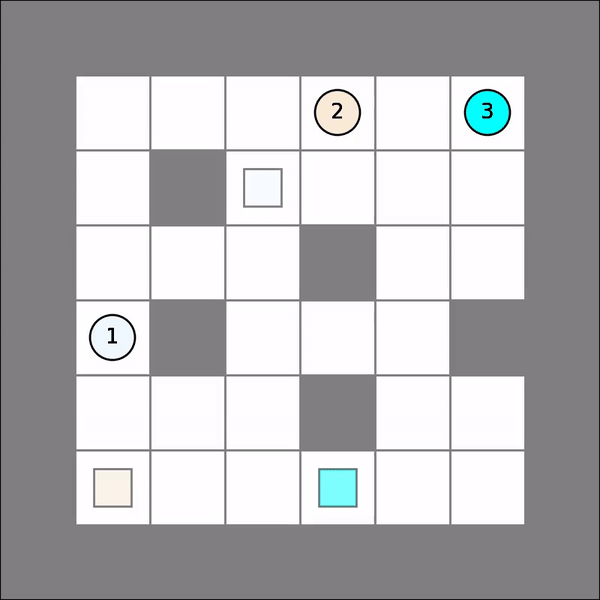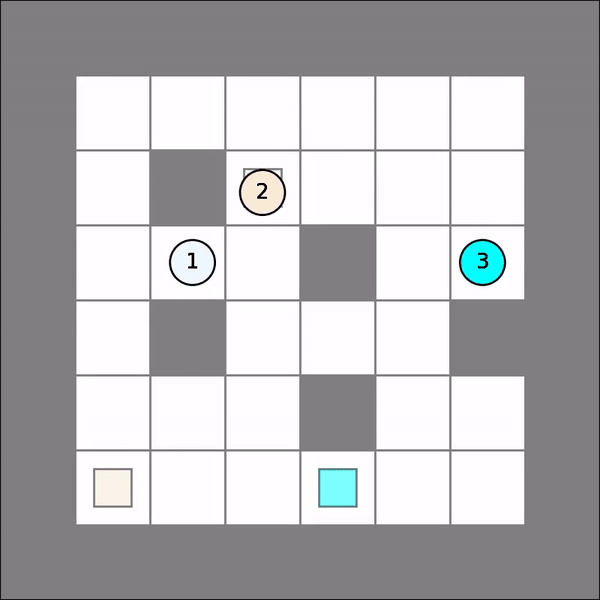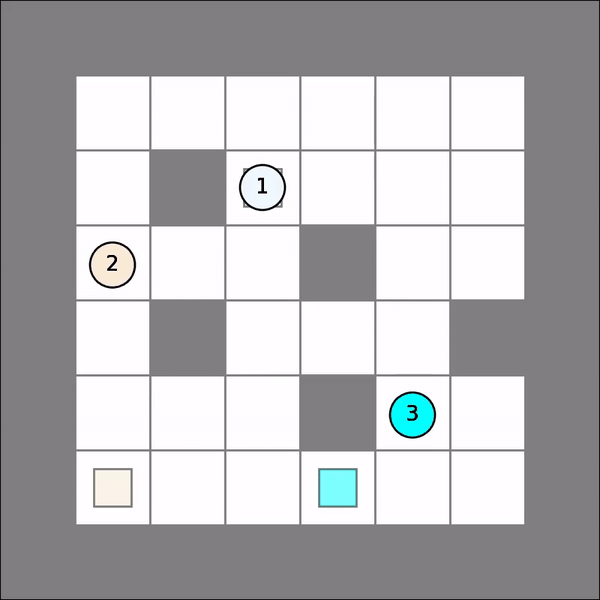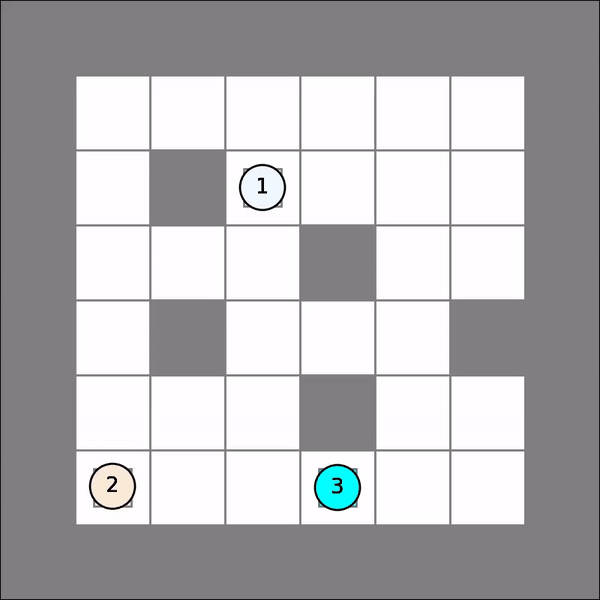
Joint Path-Finding¶
To deal with collisions explicitly, one can instead formulate a search problem over joint states and joint actions, i.e., view all agents as one single joint agent.
env.reset()
from marp.search import MultiAgentSearchWrapper, astar
joint_plan = astar(MultiAgentSearchWrapper(env))
while env.agents:
actions = joint_plan.pop(0)
env.step(actions)
env.render()
The above code has down the following things:
Formulate a joint search problem by the wrapper
MultiAgentSearchWrapper, where a state with any collision is specified as a dead end.Again, call A star search
astar(), but this time the algorithm will return a sequence of joint-actionsExecute the joint-plan.
One will probably get similar visual results as follows. Now there will not be collisions anymore.
Detailed Usage¶
Functions¶
- marp.search.astar(env)¶
Given a search environment, return the optimal plan.
- Parameters:
env (SearchEnv) – a search environment with the transition function provided.
- Raises:
RuntimeError – If no plan can be found.
- Returns:
The optimal plan.
- Return type:
list[Action]
Classes¶
- class marp.search.SingleAgentSearchWrapper(ma_env, agent)¶
Given a MARP environment, wrap it as inducing a single-agent search problem.
- Parameters:
ma_env (MARP) – a multi-agent environment with the transition function provided.
agent (str) – the agent that the problem is induced for
- get_state()¶
Obtain the underlying system state.
- Returns:
the underlying state
- Return type:
dict
- heuristic(state)¶
A domain dependent heuristic
- Parameters:
state (dict) – the state to enquire
- Returns:
the Euclidean distance from the current state to the goal state
- Return type:
float
- is_goal_state(state)¶
Check whether it is a goal state
- Parameters:
state (dict) – the state to enquire
- Returns:
whether it is a goal state
- Return type:
bool
- transit(state, action)¶
Given a state and an action, return the successor state and the cost.
- Parameters:
state (dict) – the state to enquire
action (Action) – the action to enquire
- Returns:
(the successor state, the cost)
- Return type:
(dict, float)
- class marp.search.MultiAgentSearchWrapper(ma_env)¶
Given a MARP environment, wrap it as a multi-agent joint search problem.
- Parameters:
ma_env (MARP) – a multi-agent environment with the transition function provided.
- get_state()¶
Obtain the joint state.
- Returns:
(system state, collision-free or not)
- Return type:
(dict, bool)
- heuristic(state)¶
A domain dependent heuristic: return 99999 if any collision, otherwise the sum of all agents’ costs.
- Parameters:
state (dict) – the joint state to enquire
- Returns:
the sum of the Euclidean distance of all agents’ locations to their goals
- Return type:
float
- is_goal_state(state)¶
Check whether it is a goal state
- Parameters:
state (dict) – the joint state to enquire
- Returns:
whether it is a goal state
- Return type:
bool
- transit(state, actions)¶
Given a joint state and a joint action, return the successor joint state and the aggreated cost.
- Parameters:
state (dict) – the joint state to enquire
action (dict[str, Actions]) – the joint action to enquire
- Returns:
(the successor state, the cost)
- Return type:
(dict, cost)